 This is an excerpt from the
This is an excerpt from the Agregaciones y agrupaciones
In [1]:
import numpy as np
import pandas as pd
class display(object):
"""Display HTML representation of multiple objects"""
template = """<div style="float: left; padding: 10px;">
<p style='font-family:"Courier New", Courier, monospace'>{0}</p>{1}
</div>"""
def __init__(self, *args):
self.args = args
def _repr_html_(self):
return '\n'.join(self.template.format(a, eval(a)._repr_html_())
for a in self.args)
def __repr__(self):
return '\n\n'.join(a + '\n' + repr(eval(a))
for a in self.args)
Datos de los planetas¶
In [2]:
import seaborn as sns
planets = sns.load_dataset('planets')
planets.shape
Out[2]:
In [3]:
planets.head()
Out[3]:
Agregación simple en Pandas¶
In [4]:
rng = np.random.RandomState(42)
ser = pd.Series(rng.rand(5))
ser
Out[4]:
In [5]:
ser.sum()
Out[5]:
In [6]:
ser.mean()
Out[6]:
In [7]:
df = pd.DataFrame({'A': rng.rand(5),
'B': rng.rand(5)})
df
Out[7]:
In [8]:
df.mean()
Out[8]:
In [9]:
df.mean(axis='columns')
Out[9]:
In [10]:
planets.dropna().describe()
Out[10]:
Pandas aggregations:
| Aggregation | Description |
|---|---|
count() |
Total number of items |
first(), last() |
First and last item |
mean(), median() |
Mean and median |
min(), max() |
Minimum and maximum |
std(), var() |
Standard deviation and variance |
mad() |
Mean absolute deviation |
prod() |
Product of all items |
sum() |
Sum of all items |
methods of DataFrame and Series objects.
GroupBy: Split, Apply, Combine¶
Split, apply, combine¶
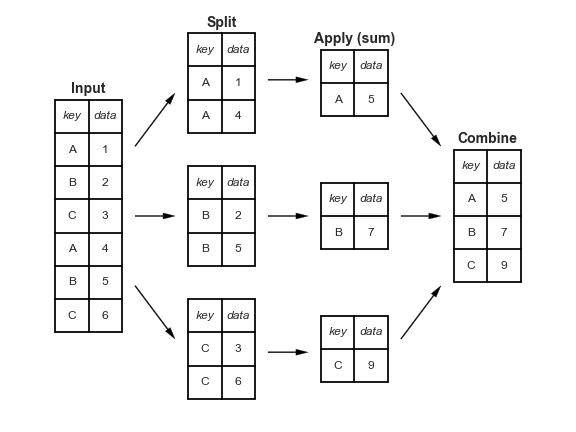
In [11]:
df = pd.DataFrame({'key': ['A', 'B', 'C', 'A', 'B', 'C'],
'data': range(6)}, columns=['key', 'data'])
df
Out[11]:
In [12]:
df.groupby('key')
Out[12]:
In [13]:
df.groupby('key').sum()
Out[13]:
The objeto GroupBy¶
Indexado por columna¶
In [14]:
planets.groupby('method')
Out[14]:
In [15]:
planets.groupby('method')['orbital_period']
Out[15]:
In [16]:
planets.groupby('method')['orbital_period'].median()
Out[16]:
Iteraciones sobre grupos¶
In [17]:
for (method, group) in planets.groupby('method'):
print("{0:30s} shape={1}".format(method, group.shape))
Métodos de envío (dispactch)¶
In [18]:
planets.groupby('method')['year'].describe().unstack()
Out[18]:
Aggregate, filter, transform, apply¶
In [19]:
rng = np.random.RandomState(0)
df = pd.DataFrame({'key': ['A', 'B', 'C', 'A', 'B', 'C'],
'data1': range(6),
'data2': rng.randint(0, 10, 6)},
columns = ['key', 'data1', 'data2'])
df
Out[19]:
Agregación¶
In [20]:
df.groupby('key').aggregate(['min', np.median, max])
Out[20]:
In [21]:
df.groupby('key').aggregate({'data1': 'min',
'data2': 'max'})
Out[21]:
Filtrado¶
In [22]:
def filter_func(x):
return x['data2'].std() > 4
display('df', "df.groupby('key').std()", "df.groupby('key').filter(filter_func)")
Out[22]:
Transformación¶
In [23]:
df.groupby('key').transform(lambda x: x - x.mean())
Out[23]:
El método apply()¶
In [24]:
def norm_by_data2(x):
# x is a DataFrame of group values
x['data1'] /= x['data2'].sum()
return x
display('df', "df.groupby('key').apply(norm_by_data2)")
Out[24]:
Especificación de la llave de separación¶
Usar lista, array, series, or indice como llave para indicar los grupos¶
In [25]:
L = [0, 1, 0, 1, 2, 0]
display('df', 'df.groupby(L).sum()')
Out[25]:
In [26]:
display('df', "df.groupby(df['key']).sum()")
Out[26]:
Usar un diccionario o series como mapeo de los indices para agrupar¶
In [27]:
df2 = df.set_index('key')
mapping = {'A': 'vowel', 'B': 'consonant', 'C': 'consonant'}
display('df2', 'df2.groupby(mapping).sum()')
Out[27]:
Cualquier función de Python¶
In [28]:
display('df2', 'df2.groupby(str.lower).mean()')
Out[28]:
Una lista de llaves válidas¶
In [29]:
df2.groupby([str.lower, mapping]).mean()
Out[29]:
Ejemplo de agrupación¶
In [30]:
decade = 10 * (planets['year'] // 10)
decade = decade.astype(str) + 's'
decade.name = 'decade'
planets.groupby(['method', decade])['number'].sum().unstack().fillna(0)
Out[30]: